

- La société mère de Tiktok, Bytedance, a dévoilé Omnihuman-1, un outil d’influence révolutionnaire.
- En utilisant une image immobile, il crée des vidéos réalistes de quiconque parle, geste ou chant.
- Il peut créer des vidéos à partir d’images de n’importe quelle taille et style, même des images de dessins animés.
ByTedance, le géant de la technologie derrière Tiktok vient de dévoiler un outil d’IA changeant la donne appelée Omnihuman-1. Cette technologie peut générer des vidéos incroyablement réalistes de personnes qui parlent, chantent, dansent et plus d’une seule image encore.

Imaginez donner vie à une image de portrait avec des gestes naturels et un audio parfaitement synchronisé. Omnihuman-1 y parvient grâce à une approche «multimodality conditionnée», combinant diverses entrées comme les images, l’audio, le texte et même les poses de corps. Cette percée repousse non seulement les limites de la génération de vidéos de l’IA, mais soulève également des questions sur l’avenir de la création de contenu et du divertissement. Mais comment cela fonctionne-t-il et comment cela s’accumule-t-il contre la compétition? Plongeons-nous.
Articles Similaires




Comment fonctionne Omnihuman-1?
À la base, Omnihuman-1 est un cadre de génération de vidéos humain «à plusieurs climatises». Cela signifie qu’il ne reposait pas sur un seul type d’entrée; Au lieu de cela, il combine intelligemment diverses sources comme une seule image, des clips audio, des descriptions de texte et même des poses de corps pour créer des vidéos réalistes.
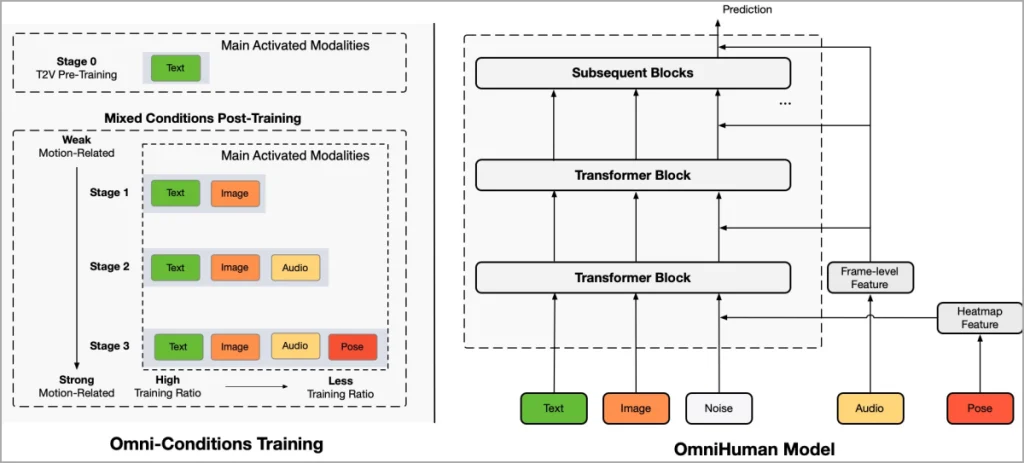
Cette approche permet à l’IA d’apprendre à partir d’un plus large éventail de données et à générer des mouvements plus subtils et précis. Pensez-y comme un conducteur menant un orchestre où chaque instrument (entrée) contribue à la symphonie finale (vidéo). En intégrant ces différents signaux, Omnihuman-1 peut produire des vidéos qui sont beaucoup plus réalistes que celles créées par des modèles s’appuyant sur des types d’entrée limités.
Le secret du succès d’Omnihuman-1 réside dans son processus de formation sophistiqué. Des chercheurs de ByTedance ont nourri l’AI un ensemble de données massif de plus de 18 700 heures de séquences vidéo humaines. Cette grande quantité de données, combinées à la stratégie de formation des «conditions omni-conditions», a permis au modèle d’apprendre les relations complexes entre l’apparence visuelle, les indices audio, les descriptions textuelles et le mouvement humain.
L’IA apprend essentiellement à relier les points entre ces différentes modalités pour prédire avec précision comment une personne dans une image calme se déplacerait et parlerait en fonction de l’audio ou du texte fourni. Cette formation approfondie, couplée à l’approche multi-entrées, est ce qui permet à Omnihuman-1 de générer des vidéos avec un réalisme aussi impressionnant, capturant des expressions faciales subtiles, des gestes naturels et des mouvements de lèvres parfaitement synchronisés.
Capacités d’Omnihuman-1: donner vie aux images
Omnihuman-1 n’est pas seulement une question de magie technique; Il s’agit de ce qu’il peut faire. Les capacités de l’IA sont vraiment impressionnantes, présentant sa capacité à transformer des images statiques en vidéos dynamiques et engageantes. Ce qui distingue Omnihuman-1, c’est le réalisme de ces vidéos générées.
Les mouvements sont fluides et naturels, les expressions faciales sont crédibles et la synchronisation labiale avec l’audio est remarquablement précise. Qu’il s’agisse d’un portrait, d’un tir à demi-corps ou d’une image pleine du corps, Omnihuman-1 peut donner vie au sujet avec une attention étonnante aux détails.
L’IA ne se limite pas aux sujets humains. Il peut également animer des personnages de dessins animés et même des animaux, ouvrant des possibilités passionnantes d’animation, de jeu et de création d’avatar numérique. Pensez à donner vie à votre personnage de dessin animé préféré avec une seule image et une voix off.
Omnihuman-1 contre la compétition
- Omnihuman-1 génère des vidéos humaines réalistes à partir d’une seule image, contrairement à de nombreux concurrents.
- Il excelle à créer des mouvements humains, des expressions et des gestes réalisants.
- L’accès de ByTedance aux données Tiktok pourrait donner à Omnihuman-1 un avantage concurrentiel du réalisme.
Omnihuman-1 rivalise avec des joueurs établis comme Sora, Runway et Luma AI d’Openai dans le domaine de la génération de vidéos AI.
Sora et Omnihuman-1 créent des vidéos en utilisant l’IA, mais ils sont bons dans différentes choses. Sora est bon pour créer des scènes réalistes. C’est génial pour construire des mondes 3D complexes et s’assurer que tout ce qui leur est en train de se déplacer de manière réaliste, comme un jeu vidéo. D’un autre côté, Omnihuman-1 est bon pour créer des vidéos de personnes. Il est bon pour que les humains aient l’air et se déplacent naturellement, avec des expressions et des gestes réalistes.
Ainsi, alors que Sora peut créer des environnements incroyables, Omnihuman-1 est mieux pour donner vie aux personnages dans ces environnements (ou dans tout environnement, d’ailleurs, car il commence par une image). Ils font tous les deux des vidéos, mais ils prennent des chemins différents pour y arriver, en se concentrant sur différentes forces.
Le Gen-3 Alpha de Runway est un autre modèle avancé connu pour son contrôle précis sur la structure, le style et le mouvement, ce qui en fait un favori parmi les créateurs de contenu professionnels. Dream Machine de Luma AI, de l’autre côté, propose une interface conviviale et prend en charge les entrées multimodales, permettant aux utilisateurs de créer des vidéos à partir des invites et des images de texte.
Omnihuman-1 se distingue de ces modèles en mettant l’accent sur la génération de vidéos humaines réalistes à partir d’une seule image, en utilisant une approche multimodale. L’accent mis sur les entrées minimales et les divers flux de données le distingue. Alors que certains concurrents se concentrent sur la génération de vidéos à partir d’invites de texte ou nécessitent plusieurs images, Omnihuman-1 crée un mouvement réaliste à partir d’une seule image immobile.
De plus, l’accès de Bytedance à de grandes quantités de données vidéo via Tiktok pourrait donner à Omnihuman-1 un avantage concurrentiel dans la formation de son IA pour comprendre le comportement humain et générer des résultats encore plus réalistes.
Quand pouvez-vous mettre la main sur Omnihuman-1?
Alors qu’Omnihuman-1 a généré une excitation significative avec ses manifestations impressionnantes, il est important de noter qu’il est actuellement Toujours en phase de recherche. ByTedance n’a pas encore publié l’outil au public. Cela signifie que vous ne pouvez pas le télécharger, l’essayer ou l’utiliser pour vos propres projets vidéo pour l’instant.
Cependant, les chercheurs ont partagé des exemples de vidéos et de détails sur la technologie, ce qui suggère qu’ils pourraient envisager une version plus large à l’avenir. Il est également possible que les éléments de la technologie d’Omnihuman-1 puissent éventuellement être intégrés dans des produits de bydance existants comme Tiktok ou Capcut, ce qui rend ses capacités accessibles à un public plus large. Pour l’instant, cependant, nous devrons attendre et voir quels sont les plans de Bytedance pour cet outil d’IA prometteur.
Ce n’est que le début d’Omnihuman-1, et nous avons hâte de voir la prochaine étape! Restez à l’écoute pour d’autres mises à jour.













{kind=link}